PLASMA
Initial situation
Research into heterogeneous data and its integration is an ongoing process that has become increasingly important over time. The need to link and integrate different data sources has existed for a long time. However, the increasing availability and utilisation of different data sources has led to an increased focus on the research and development of methods for processing heterogeneous data in recent decades. In the 1990s, researchers began to focus more on the integration of heterogeneous data sources. Various approaches and techniques were developed to meet the challenges of processing, integrating and analysing heterogeneous data. With advances in database technology, the development of standards for data exchange and the increasing importance of big data and data integration, research into heterogeneous data sources has evolved. Today, this is an active and dynamic field of research. One research approach is semantic data management.
Semantic modelling
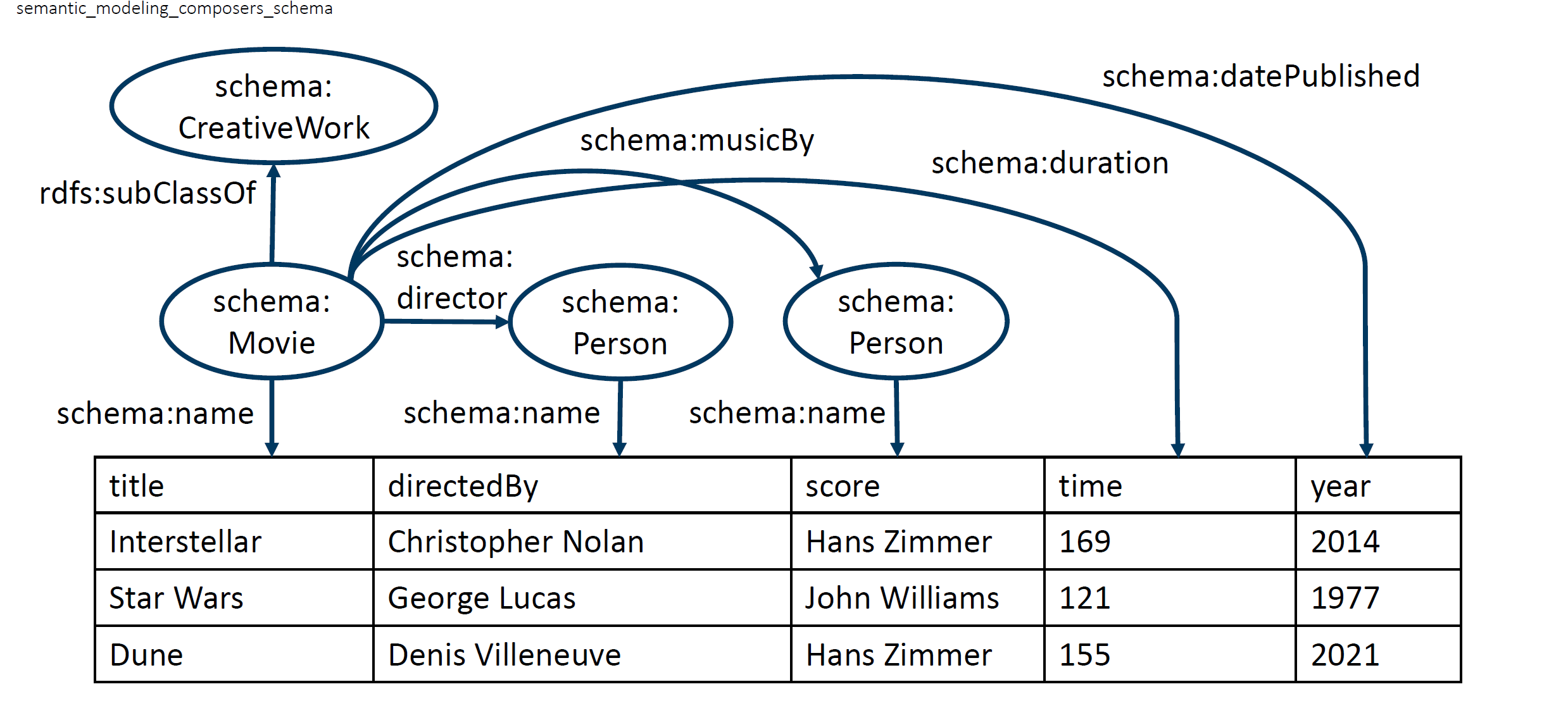
In the field of semantic data management, the use of common conceptualisations such as knowledge graphs or ontologies has proven to be particularly effective for efficiently managing and consolidating heterogeneous data sources. For example, based on an existing ontology, all data attributes of the existing data records are mapped to classes of this ontology. This process is known as semantic labelling and enables the data attributes to be interpreted within the framework of the ontology. In order to obtain a fine-grained description of the data, the creation of a semantic model is the established approach.
However, the manual creation of semantic models requires specialised knowledge and is time-consuming. Today, there are already various automated and semi-automated approaches to support the creation of a semantic model. Various information from and about the data sets to be annotated (labels, data, metadata) is used to create semantic labels and complete semantic models. However, automated approaches are limited in their applicability in real-world scenarios for various reasons and therefore require manual post-processing. This post-processing is known as semantic refinement. This is usually done by domain experts, i.e. users who know the data very well but usually have little or no knowledge of semantic technologies.
Our research addresses these two challenges. Our research focuses both on the improved automatic generation of semantic labels and models using machine learning methods and on the efficient and semi-automated post-processing (e.g. using recommendation systems) of automatically generated semantic models. In doing so, we pursue the overarching goal of making semantic modelling practical and scalable.
The PLASMA Framework
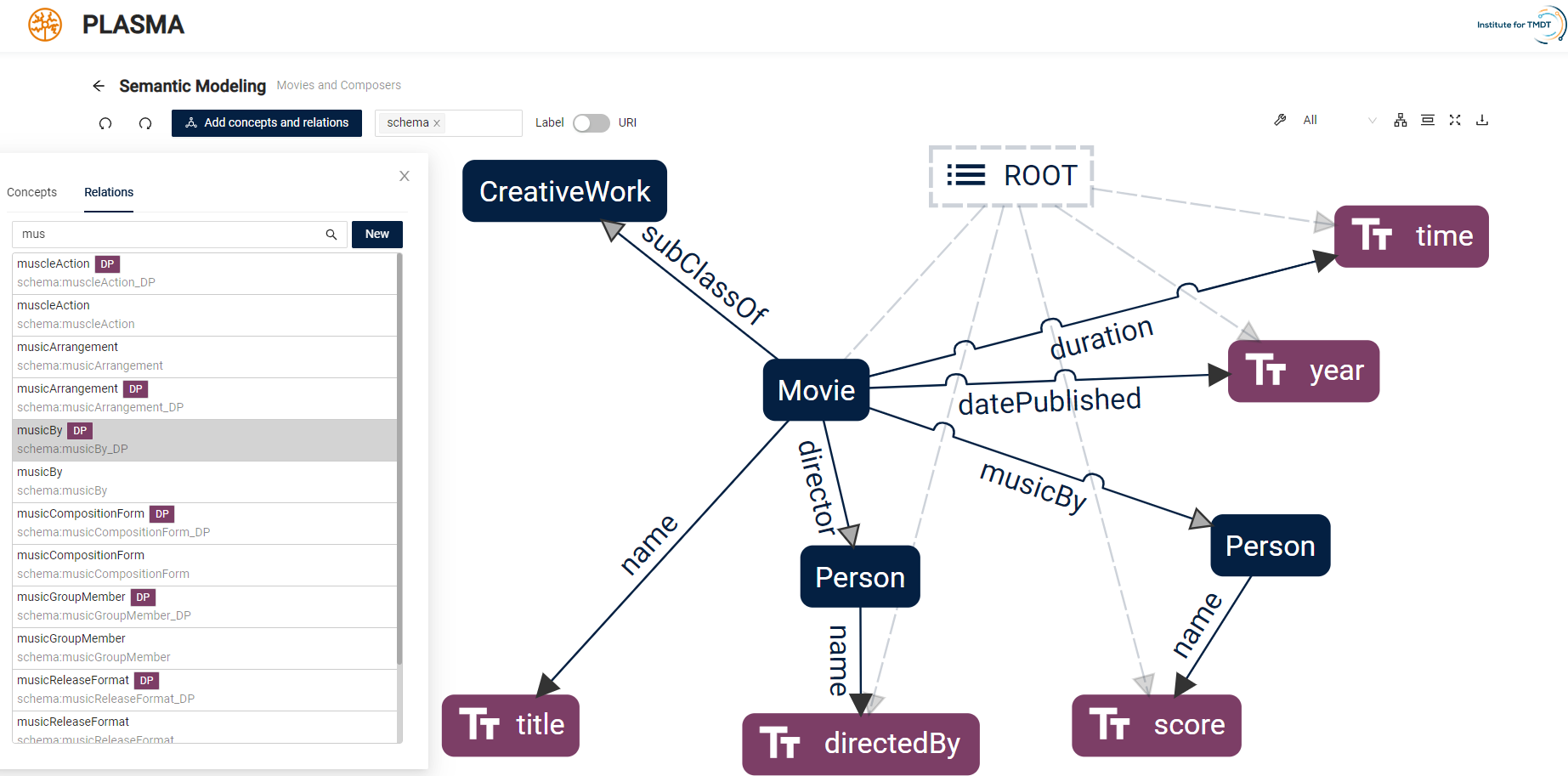
A key result of our research is the PLASMA framework. PLASMA is a tool for creating and editing semantic models that is primarily aimed at non-specialist users. We presented the first version of this semantic modelling platform in 2021 and have been continuously developing it further. PLASMA offers an easy-to-use graphical user interface to lower the barrier to entry for users with no experience of semantic modelling. PLASMA handles all interactions related to the modelling process, manages its own ontologies and a knowledge graph, and is able to analyse input data to identify its schema. In addition, the interfaces and libraries provided by PLASMA enable direct integration into data spaces. Thanks to the underlying microservice architecture, various existing approaches for automated semantic modelling can also be integrated into the process. PLASMA is open source and can be tested here.
Applications
Our research is applied in all contexts that deal with semantic data management (finding and integrating semantic data) or wherever mappings between conceptualisations and data are required. Today, these are in particular the areas around data spaces, the development of knowledge graphs and data management according to the FAIR principles.